FYP EPS1: Get the ideas of Content-Based Recommendation Engine.
Hello everyone!
After two weeks of stressed out (I guess I’m always writing about “I’m stressed out” ahahaha) about my final year project. Anyways, I finally found a solution for my system engine. Basically, my system is about, the resume content is automatically recommended by the system especially skills. Which is, really good to use if you have no idea what to put in your resume. This system is actually something that comes from my problem where I don’t really like to spend so much time creating a few resumes for another job scope. I know, there’s a ton of online tools that can help you out to create a resume with a simple click.. but the question is.. are they really help you in terms of your skills and your chosen job? Nope. They’re gonna suggest you pre-written phrases based on WHAT SKILLS THAT YOU HAVE and not WHAT SKILLS THAT YOU NEED TO PUT ON YOUR RESUME. Well, my system will recommend the content, based on the user profile and chosen job.
There’s a lot of algorithms that can actually measure the similarity of the “keywords”. The question is, how similar they can give? So, in two weeks, I spend my time to search the perfect algorithm and it turns out that the “cosine similarity metric” is the right one! Why? Because it has two vectors that can calculate the angle in a 2D array. The two vectors are arrays that contain the “words count” of two documents.
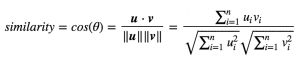
If the two vectors are identical, it will be 1 and it will be 0 if the two are orthogonal. At first, I just want to use a basic filter, as the number of common words might be a perfect engine to implement in my system. However, it is not good as cosine. Why? Just imagine if document A has 400 data common words and document B has 100 data common words. Which document will win? Of course A. Because the common words in document A are higher than in document B. So, that’s why it is not a perfect approach. If we use cosine, then the angle will be judged in terms of similarity. The closer the documents are by angle, the higher is the cosine similarity.
The engine for getRecommendation() is already done! Phewwww. However, I’m still working on this project and I will push it to GitHub as public… soon! Right now, I’m in the logic thinking phase for my Entity Relationship Diagram (ERD) and its attribute.



